
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- grad-cam
- xai
- 코딩 테스트
- 코딩테스트
- GAN
- meta-learning
- Unsupervised learning
- Score-CAM
- Machine Learning
- SmoothGrad
- 딥러닝
- cs231n
- python
- Deep learning
- 머신러닝
- Interpretability
- 시계열 분석
- 기계학습
- Explainable AI
- AI
- 백준
- Cam
- 메타러닝
- keras
- Artificial Intelligence
- 설명가능한 인공지능
- Class activation map
- 인공지능
- 설명가능한
- coding test
- Today
- Total
iMTE
Understanding and Visualizing Convolutional Neural Networks 본문
Understanding and Visualizing Convolutional Neural Networks
Wonju Seo 2019. 3. 2. 17:13Reference :
http://cs231n.github.io/understanding-cnn/
http://aikorea.org/cs231n/understanding-cnn/
Visualizing what ConvNets learn
Convolutional networks를 이해하고 시각화하기 위한 여러 가지 접근법이 개발되었는데, 부분적으로는 neural networks에서 학습 된 기능을 해석할 수 없다는 일반적인 비판에 대응한다. (이런점에서 학습된 feature들을 보여주는 것은 explainable AI 분야에서 매우 중요하다. 워낙 Black box라고 해서 신뢰를 못한다는 등의 비판이 많다. (그렇게 신뢰되는 Kernel SVM도 마찬가지 아닌가?))
Visualizing the activations and first-layer weights
가장 직접적인 visualizing 기술은 forward pass 중에 networks의 activation을 표시하는 것이다. ReLU network의 activation은 일반적으로 상대적으로 작고 밀도가 높은 것으로 시작하지만 training이 진행됨에 따라 activation은 일반적으로 보다 sparse해지고 localized 된다.


위의 첫 convolutional layer (왼쪽)의 activation 및 다섯 번째 convolutional layer (오른쪽)의 activation을 보여주고 있다. 각 filter에 해당하는 activation map이 표시되는데, 검은색은 0을 가리킨다.
Conv/FC filter
두 번째 visualization 전략은 weight을 시각화하는 것이다. filter의 weights을 표시한다. Noisy한 pattern은 충분히 길게 학습되지 않은 network의 지표일 수 있으며, over-fitting이 되었거나, 낮은 정규화 강도를 가진 경우로 볼 수 있다. (매끄러운 pattern은 weight이 잘 학습되었다는 것을 의미한다.)


Retrieving images that maximally activate a neuron
또 다른 시각화 기술은 이미지의 큰 데이터 set을 가져와서 network를 통해 공급하고 어떤 이미지가 일부 뉴런을 최대한 활성화하느지 추적하는 것이다. 그런 다음 이미지를 시각화하여 receptive field에서 neuron이 찾고 있는 것을 이해할 수 있다.

특정 neuron의 활성화 값과 receptive field는 흰색으로 표시된다.
이 접근법의 문제점은 ReLU neuron이 반드시 semantic 의미를 가질 필요는 없다는 것이다.
Embedding the codes with t-SNE
Image를 2차원으로 embedding하여 low dimension representation이 high dimension representation보다 거의 동일한 거리를 갖도록 함으로써, 저차원공간에 고차원 vector를 embedding하는 방법들이 있다. 이 중 t-SNE는 시각적으로 만족스러운 결과를 생산해낸다. (꽤 많은 논문들이 시각화를 할 때 t-SNE를 사용한다.) 밑의 그림은 t-SNE의 결과를 보여주고 있다. 서로 가까이에 있는 이미지는 CNN 표현 공간에서도 가깝다. 이는 CNN이 이미지의 유사함을 학습했다고 볼 수 있는 것이다. 이 유사점은 pixel 및 color의 low level의 feature라기보다는 semantic인 경우가 많다. (파란색 자동차는 파란색 냉장고와 거리가 멀고, 빨간색 자동차와 거리가 가깝다.)

Occluding parts of the image
ConvNet이 이미지를 개로 분류한다고 가정해보자, 정말로 개가 있다는 것을 어떻게 확신할 수 있을까? 이미지에서 개를 지워보고 개에 해당하는 확률을 계산한다면, ConvNet의 의사 결정 과정을 어느정도 이해할 수 있을 것이다.
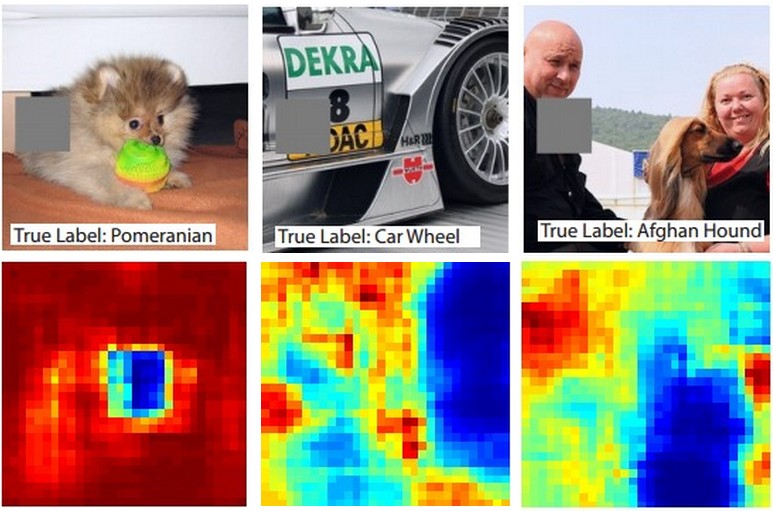
위의 그림은 Occluder를 이미지 위로 넣으면서 class의 확률을 구한다음 heatmap으로 시각화한 결과다. 예를 들어, 가장 왼쪽의 이미에서 강아지 얼굴이 개 얼굴을 덮을 때 Pomeranian의 확률이 떨어지는 것을 볼 수 있다. 두번째 예로는 타이어를 가리는 경우 (Car wheel), 세번째 예로는 개를 가리는 경우 (Afghan Hound)에 class의 확률이 감소하는 것을 확인할 수 있다.
(이런 결과는 매우 흥미롭다. 단순히 무작위적으로 의사 결정을 하는 것이 아닌, 근거를 기반으로 의사 결정을 한다는 것이고 이는 Neural network를 이해할 수 없는 black box라고 할 수 없는 근거가 된다.)
'Deep learning study > CS231n' 카테고리의 다른 글
| Transfer Learning and Fine-tuning Convolutional Neural Networks (0) | 2019.03.02 |
|---|---|
| Convolutional Neural Networks: Architectures, Convolution / Pooling Layers (0) | 2019.03.02 |
| Neural Networks Part 3: Learning and Evaluation (0) | 2019.03.02 |
| Neural Networks Part 2: Setting up the Data and the Loss (0) | 2019.03.02 |
| Neural Networks Part 1: Setting up the Architecture (0) | 2019.03.01 |