
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 인공지능
- 코딩 테스트
- 코딩테스트
- Interpretability
- xai
- 기계학습
- 설명가능한
- GAN
- Score-CAM
- AI
- 시계열 분석
- SmoothGrad
- 설명가능한 인공지능
- Machine Learning
- meta-learning
- Unsupervised learning
- 백준
- 메타러닝
- 딥러닝
- Cam
- grad-cam
- keras
- python
- Class activation map
- coding test
- Deep learning
- Artificial Intelligence
- Explainable AI
- cs231n
- 머신러닝
- Today
- Total
iMTE
[GAN] Stitch it in Time: GAN-Based Facial Editing of Real Videos 본문
[GAN] Stitch it in Time: GAN-Based Facial Editing of Real Videos
Wonju Seo 2022. 4. 13. 15:46논문 제목 : Stitch it in Time: GAN-Based Facial Editing of Real Videos
논문 주소 : https://arxiv.org/abs/2201.08361
Youtube video : https://www.youtube.com/watch?v=4lQkQSmA8nA
Stitch it in Time: GAN-Based Facial Editing of Real Videos
The ability of Generative Adversarial Networks to encode rich semantics within their latent space has been widely adopted for facial image editing. However, replicating their success with videos has proven challenging. Sets of high-quality facial videos ar
arxiv.org
주요 내용 정리:
1) (보통 GAN을 사용하여 Video 의 각 frame의 editing을 하는데 있어서, 단순히 image에서 사용한 것을 이어붙이는 등의 방법을 사용하는 경우에는 frame 사이의 연속성이 나쁜 문제가 있다. 이를 해결하기 위해서 저자는 StyleGAN 기반의 pipeline 알고리즘을 제안하였고, 이 알고리즘은 기존 방법에 비해서 상당히 좋은 성능을 보였다.) 저자는 자연스러운 video editing을 위해서 밑의 그림과 같은 pipeline 을 제안하였다.

(1) 먼저, video의 각 frame에서 face를 추출 하고 align한다. (2) 미리 학습된 e4e encoder을 사용해서 cropped face를 미리 학습된 StyleGAN2 model의 latent space에 매핑한다. (3) PTI (pivotal tuning for latent-based editing) 을 사용하여 generator를 fine-tune 한다. (4) 모든 frames 들은 pivot latent codes 를 선형적으로 manipulation 한 것으로 수정된다. (5) generator를 fine-tune 하고 edited face와 background 를 stitching 한다. (6) 마지막으로, face를 다시 original frame 에 맡게 alignment 하고 붙여넣는다.
(2-3) 과정을 수식적으로 분석해보면 다음과 같다.
주어진 N개의 frames은 다음과 같이 표현되며, cropped-and-aligned frames은 에서 추출된다.
,
e4e Encoder 를 사용해서 latent inversion을 얻어낸다.
이 latent vectors 들은 PTI을 위한 'pivots'으로서 사용된다. 다음 추출된 latent vector 로 부터 에 의해 생성된 image를 다음과 같이 나타낸다.
PTI의 objective는 다음과 같다.
위 식에서 와 은 다른 연구에서 제안된 loss, 는 pixel-wise MSE distance를 의미한다. 값들은 constants이다.
(4) editing 과정에서는 다음과 같은 수식으로 edited frame을 얻는다.
위 식에서, 는 semantic latent edicting direction, 는 PTI-weights을 의미한다.
(5)의 과정은 stitching tuning 으로 다음 그림에서 그 방법이 소개되어 있다.
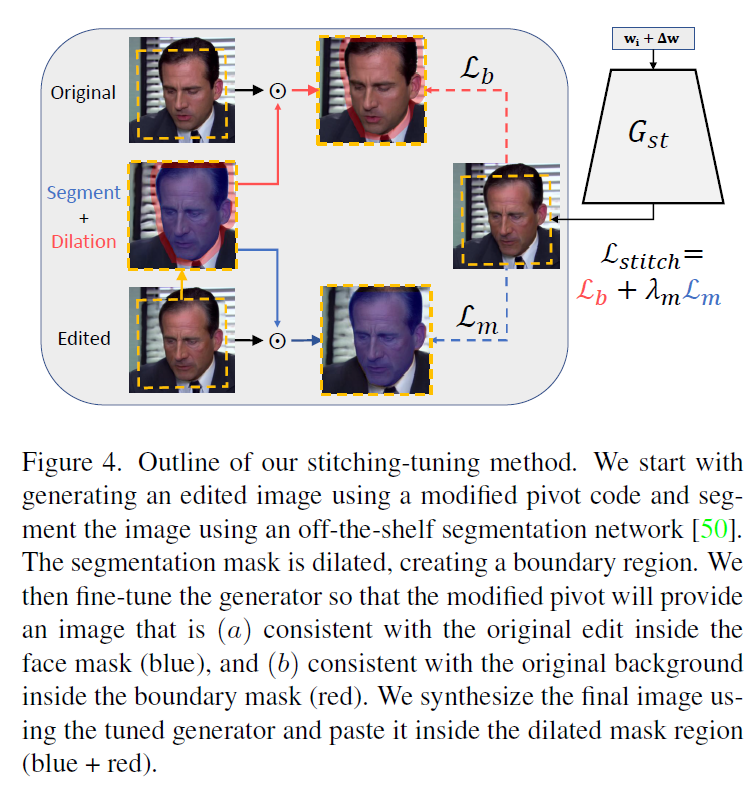
Stiching 방법은 frame에서 editing 이후에 발생하는 boundary 에서의 artifacts를 제거하기 위한 방법으로 볼 수 있다. 수식으로 보면 좀 더 잘 이해할 수 있다.
Off-the-shelf pre-trained segmentation network으로 생성된 segmentation mask는 다음과 같다.
다음으로, expanded masks를 얻기 위해서 dilation 을 적용시킨다.
boundary는 segmentation mask와 expanded mask의 XOR 연산으로 얻어진다.
Stitching tuning procedure의 결과를 다음과 같이 나타낸다.
이 단계에서 두개의 objective가 있으며 다음과 같다.
이 두 objective는 generator weights 를 최적화하는데 사용된다.
위 식에서 는 PIT의 weights 로 초기화가 되며, 은 상수이다.
(6) 과정은 inverted alignment를 수행하고, each frame 을 origial frame 에 stich 한다. 이때, dilated masks 이 사용된다.
2) Figure 3과 Figure 9 (Ablation study)을 보면 제안된 pipeline에서 각 알고리즘이 어떤 역할을 하는지 알 수 있다.


다음으로 제안된 pipeline의 성공적인 사례의 결과들을 보면, 상당히 잘 editing 되었음을 알 수 있으며, 기존 방법대비 artifcats가 적은 것을 볼 수 있다.




또한 사람의 얼굴이 아닌 animation 에도 적용할 수 있는 특징이 있다. (out-of-domain problem)

+
StyleGAN, e4e encoding 등의 기존의 제안된 방법을 사용하여 video edting의 성능을 향상시킨 알고리즘을 저자가 제안하였다. Video 내의 temporal dependency를 직접 모델을 사용해서 해결하려기보다는, 이미 video의 original frame이 temporal consistent를 갖고 있으니, latent space에서 크게 변화가 되지 않게끔만 조정을 하여 다시 복구해내면 consistency를 유지할 수 있을 것이라는 가정을 사용하였다. 또한, face 만 수정하게 되는 경우에 발생하는 boundary 에서의 artifacts를 제거하기 위해서 segmentation mask를 사용하는 것은 매우 그럴 듯 해보인다. 주요하게 볼 점은 300 frames video에 1.5 시간이 걸린다고 하니 꽤 컴퓨테이션이 많은 것으로 보인다. 그도 그럴 것이 off-the-shelf 단계들이 있다.
'Deep learning study > Recent papers' 카테고리의 다른 글
| Recent papers category (0) | 2022.04.13 |
|---|