
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Machine Learning
- 코딩테스트
- SmoothGrad
- grad-cam
- keras
- 기계학습
- Score-CAM
- 설명가능한
- 설명가능한 인공지능
- 메타러닝
- 인공지능
- 코딩 테스트
- Deep learning
- 머신러닝
- 백준
- meta-learning
- coding test
- Cam
- Artificial Intelligence
- GAN
- 딥러닝
- Unsupervised learning
- xai
- 시계열 분석
- Explainable AI
- Class activation map
- python
- AI
- cs231n
- Interpretability
- Today
- Total
iMTE
CAMERAS: Enhanced Resolution And Sanity Preserving Class Activation Mapping For Image Saliency 내용 정리 [XAI-24] 본문
CAMERAS: Enhanced Resolution And Sanity Preserving Class Activation Mapping For Image Saliency 내용 정리 [XAI-24]
Wonju Seo 2021. 11. 16. 17:41논문 제목: CAMERAS: Enhanced Resolution And Sanity Preserving Class Activation Mapping For Image Saliency
논문 주소: https://arxiv.org/abs/2106.10649
CAMERAS: Enhanced Resolution And Sanity preserving Class Activation Mapping for image saliency
Backpropagation image saliency aims at explaining model predictions by estimating model-centric importance of individual pixels in the input. However, class-insensitivity of the earlier layers in a network only allows saliency computation with low resoluti
arxiv.org
주요 내용 정리:
1) 얕은 layer에서의 features는 class-insensitive하며, 깊은 layer에서의 features는 high-level feature로 유용하지만 low resolution feature map을 갖는 문제점이 있다. 저자는 CAMERAS (Enhanced Resolution And Sanity preserving Class Activation Mapping for backpropagation image saliency)라는 새로운 방법의 gradient-based class activaiton mapping 방법을 제안하는데, 이 방법은 여러 layers들의 activaiton maps과 gradients를 fusion 함으로써, highly precise CAM을 생성해낸다. 밑의 그림은 이 방법의 전체적인 개요를 보여준다. Top figure에서는 제안된 CAMERAS 방법이 precise saliency map을 생성해내기 위해서, multi-scale activation maps과 backpropagated gradients를 fusion 한다는 것이다. Bottom figure는 CAMERAS가 쉽게 sanity check를 통과하는 것을 보여주는데, 이는 이 방법이 heuristic, priors, thresholds 등의 external factors에 영향을 받지 않기 때문이라고 저자는 이야기하고 있다.

External influences를 피하는 방법은 쉽게 sanity check를 통과할 수 있는데 (예, Grad-CAM), 이를 위해서는 주어진 정보만 사용하는 것이 중요하다. 먼저, Grad-CAM은 다음과 같이 표현된다.
wk=1(m+n)m∑i=1n∑j=1(∂yl∂A(i,j)k)
I∈Rc×h×w 는 'c' channels 을 가진 input image, K(I) 는 I를 prediction vector yl∈RL로 mapping 하는 a deep visual classifier 이다. 여기서 L은 전체 class의 개수이며, l은 I에서 예측된 label 이다.
위 wk 식에서, Ak(I)∈Rm×n은 마지막 convolutional layer에서 kth activation map을 의미하고, S(I)∈Rm×n은 S(i,j)(I)=∑kwkA(i,j)k(I)를 나타낸다.
Final saliency map은 다음과 같이 표현된다.
Ψ∈Rh×w=f(S)
위 식에서 f()는 m×n matrix를 h×w matrix로 interpolating 하는 함수이다.
2) Grad-CAM은 두가지 문제점이 있음을 저자가 지적한다.
(1) Over-simpliation of the weights wk:
Individual pixel에 대해서 importance를 계산하는 것이 아닌 특정 activation map에 대해서 importance를 계산한다는 점이다. 따라서, 밑의 식과 같이 individual backpropagated gradients를 고려하도록 한다.
S=∑kWk⊙Ak
(2) Large interpolated segments:
Deep layer의 activation map은 input image에 비해서 매우 작은데, 최종적으로 interpolating을 통해서 input image size로 resize를 한다. 이때, heuristic과 같은 external information을 사용하는 경우가 있는데, 이 방법으로 인해서 original model에 기반한 방법이 아님으로 sanity check를 fail하는 문제를 일으킨다.
저자는 이 두 문제를 해결하기 위해서, multiple layers로 부터 획득되는 정보를 바탕으로 이 이슈들을 극복하고자 하였다.
제안되는 salinecy map은 다음과 같이 나타낸다.
Ψ=f(ReLI(∑kW∗k⊙A∗k)),∀k
위 식에서 W∗k∈Rh×w 는 kth activation map의 backpropgated gradients의 differential information을 encoding 하며, A∗k∈Rh×w 는 activation map 그자체의 enhanced resolution encoding이며, f()는 element-wise normalisation [0,1]을 수행하는 함수이다.
W∗k=Et[ρt(Wk(ρt(I,ζt)),ζ0)]
A∗k=Et[ρt(Ak(ρt(I,ζt)),ζ0)]
위 식에서 ρt(X,ζt)는 tth up-sampling으로 X에서 ζt dimension으로 resize하는 함수이고, ζ0=(h,w)로 input image I에 맞게 고정하였다. W(i,j)k 는 (∂yl∂A(i,j)k)로 정의된다. CAMERAS의 algorithm은 밑의 그림에 표시되어 있다.

위 알고리즘은 반복적으로 kth activation map에 대한 activation maps과 gradients에 대해서 multi-scale accumulation을 통해서 saliency map을 형성한다.
(line 4-5) tth iteration 에서 I는 maxium desired size ζm에 기반한 ζt 크기로 up-sampling이 되며, N은 ζm에 도달하기 위한 steps을 의미한다.
(line 6-10) Input up-scaling은 model의 prediction에 영향을 주지 않는 한, kth layer의 activation map과 backpropagated gradients도 up-sample되고 stored 된다.
(line 9) 새롭게 선언된 ∇J(K,l)은 predicted label l에 대한 kth layer의 collective backpropgated gradients를 의미한다.
(line 8-9) Activation map과 gradients는 original image size ζ0에 맞게 up-sampling 된다.
(line 12-13) Up-sampled 된 activation map과 gradients를 accumualte 하고 최종적으로 average를 계산한다.
위 알고리즘에서 k는 last convolutional layer로 고정되었는데 이는 CNN에서 깊은 layers가 class-sensitivity하기 때문이다. ζm=cNζ0로, c는 step size로 정의된다.
CAMERAS에서는 saliency map에 대해서 어느 prior도, heuristic도 쓰질 않았고, 이로 인해서 sanity check를 pass할 수 있게 되는 것이다. 그리고 ρ()는 bi-linear interpolation으로 고정하였다.
(이후에 나오는 lemma, corollary를 설명하면서 왜 CAMERAS가 뛰어난 성능을 보여주는지에 대해서 설명하는데 이 부분은 관심이 있으면 논문에서 읽어보는 것을 추천한다.)
3) Results
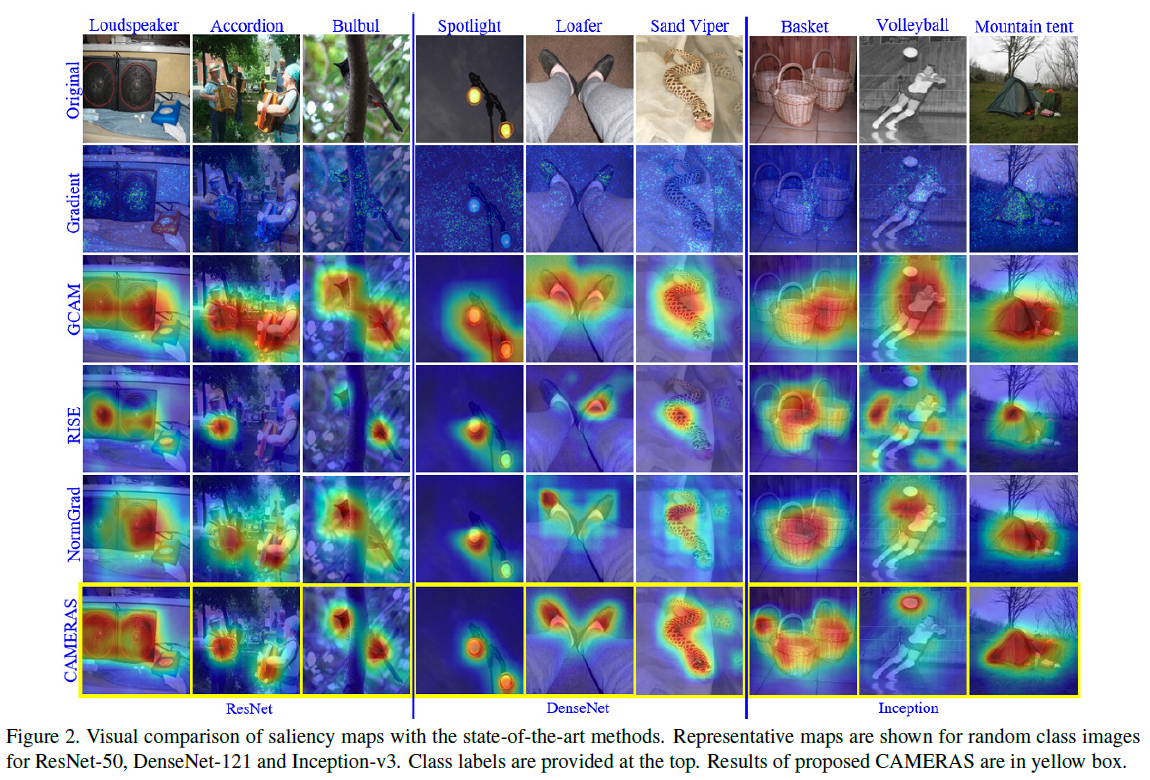
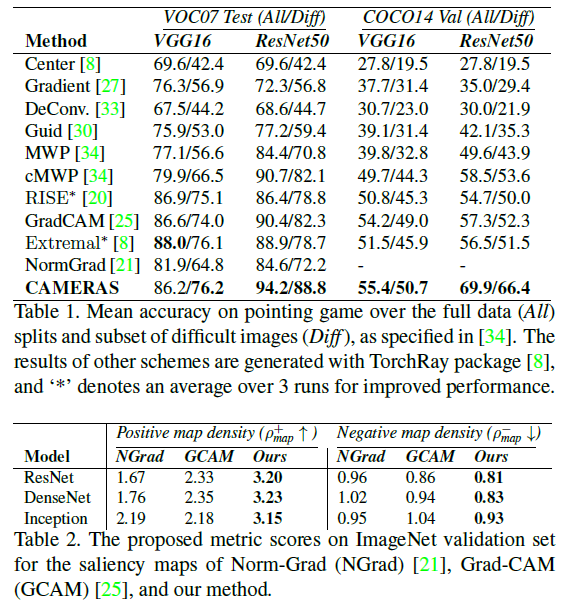
위 그림에서 제안된 CAMERAS가 기존 방법대비 매우 precise 한 salinecy map을 생성하는 것을 알 수 있다. 또한, quantitative results에서도 CAMERAS는 상당히 좋은 성능을 보여주었다. (여기서 positive map density, negative map density에 대해서 설명해주는데, 이 부분도 관심이 있다면 논문을 읽어보길 바란다. 이 두 성능은 saliency map의 quality에 대해서 평가한다.)
CAMERAS 는 주요한 특징이 있다.
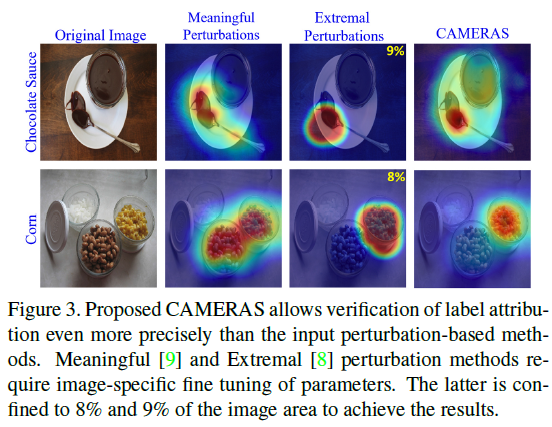
(1) The label attribution problem:
밑의 그림을 보면 input perturbation-based method보다 CAMERAS가 더 정확하게 label attribution을 보여주고 있음을 알 수 있다.
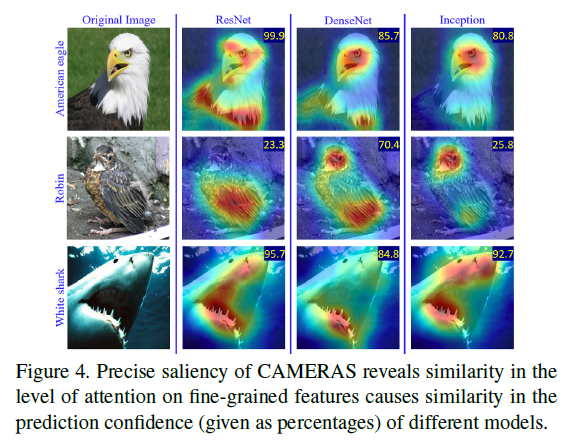
(2) Prediciton confidence:
밑의 그림을 보면 CAMERAS는 individual images의 prediction confidence는 fine-grained features에 대해 model의 attention에 강력하게 영향을 받는다는 것이다. 다른 visual models (ResNet, DenseNet, Inception) 들이 비슷한 attention을 갖고 비슷한 confidence score를 갖는다.
(3) Discrimination of similar objects:
밑의 그림을 보면 비슷한 형태의 feature가 사용되었지만 서로 다른 label을 갖는 경우, CAMERAS는 다른 activaiton map을 보여주고 있다. Chain-line fence의 경우 individual chain knots을 activation 하고 있는 반면, swing의 경우 large chain structure를 activaiton 하는 모습을 볼 수 있다.

4) Adversarial attack enhancement
Attack 시에 projected gradient descent (PGD)는 강력한 attack 방법으로 고려된다. 이 방법을 바탕으로 CAMERAS를 사용해 좀 더 개선된 attack 방법을 제안하였다.
minp(J(Ip,lll)+β||p⊙(1−Ψ)||2),
위 식에서 Ip는 perturbed image, J()는 cross entropy loss, lll은 clean image의 least likely label 이고, p는 purturbation을 나타낸다. 여기서 β는 50으로 정해졌다. CAMERAS 방법은 가장 중요한 부분에 영향을 줌으로써, required perturbation norm을 급격하게 줄였다. 밑의 그림을 보면, Enhanced PGD는 기존 PGD 보다 visual percetable한 부분을 매우 줄였음을 알 수 있다.

+
저자는 기존 CAM 기반의 문제점들을 해결하기 위해서 여러 layers들의 activation maps과 gradients를 fusion 한 CAMERAS라는 새로운 방법을 제안하였으며, 이 방법의 우수성을 기존 모델과 비교하여 보여주었다. 또한, adversarial attack에 대해서도 상당히 눈으로 확인하기 어렵게 attack sample을 만들 수 있음을 보여줌으로써 유용한 applicaiton으로 사용될 수 있음을 보였다. 아쉬운 점은 computation cost에 대해서 비교를 하는 표가 필요하지 않나 싶다.



