
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- coding test
- 백준
- 설명가능한
- 시계열 분석
- 기계학습
- xai
- 인공지능
- GAN
- python
- Interpretability
- 메타러닝
- keras
- AI
- SmoothGrad
- 코딩테스트
- Explainable AI
- Unsupervised learning
- Class activation map
- cs231n
- 머신러닝
- Machine Learning
- meta-learning
- 코딩 테스트
- 설명가능한 인공지능
- Deep learning
- Artificial Intelligence
- Score-CAM
- Cam
- grad-cam
- 딥러닝
- Today
- Total
TestK
Towards Better Explanations of Class Activation Mapping 내용 정리 [XAI-22] 본문
Towards Better Explanations of Class Activation Mapping 내용 정리 [XAI-22]
Wonju Seo 2021. 9. 30. 17:14논문 제목 : Towards Better Explanations of Class Activation Mapping
논문 주소 : https://arxiv.org/abs/2102.05228
Towards Better Explanations of Class Activation Mapping
Increasing demands for understanding the internal behavior of convolutional neural networks (CNNs) have led to remarkable improvements in explanation methods. Particularly, several class activation mapping (CAM) based methods, which generate visual explana
arxiv.org
주요 내용 정리 :
1) 저자는 기존 CAM에서 사용되는 important weights 대신에, SHAP values를 approximation 하는 LIFT-CAM을 제안하여, 기존 CAM 방법보다 월등한 성능을 보여주었으며, VQA에서도 Grad-CAM보다 더 나은 설명력을 보여줌을 확인하였다. 최근 리뷰한 Ablation-CAM 보다 더 성능이 좋으면서 efficient 한 방법으로, 추후 분석에 사용되기에 유용할 것이라고 예상된다.
2) 먼저, CAM은 다음과 같이 나타낸다.
$$ L_{CAM}^c (A) = ReLU(\sum_{k=1}^{N_l} \alpha_k A_k)$$
위 식에서 $c$는 target class, $f^c(x)$는 target class $c$에 대한 input image $x$의 output, $A=f^{[l]}(x)$ 는 input image $x$의 $l$-th layer의 output, $A_k$는 $A$의 $k$-th feature map, $\alpha_k$는 $A_k$의 coefficient (importance)를 의미한다.
다음으로 Shapley additive explanations (SHAP)은 다음과 같이 나타낸다. (Eq. 2)
$$g(z')=\phi_0 + \sum_{i=1}^M \phi_i z_i'$$
위 식에서 $g$는 target class $c$ 와 input $x$에 대한 model $f$의 original prediction의 explanation model, $M$은 input features의 갯수, $z'\in \{0,1\}^M$ 특정 input feature의 여부를 가리키는 binary vector, $\phi_i$는 $i$-th feature, $\phi_0$는 baseline explantion을 의미한다.
위 식은 $z'\approx x'$ 일때마다, $g(z')\approx f^c(h_x(x'))$이도록 설계되었고, $h_x$는 mapping function 으로 $x=h_x(x')$을 만족한다.
Eq.2 는 local accuracy, missingness, consistency를 만족한다.
SHAP values는 다음과 같은 공식으로 계산된다.
$$\phi_i \sum_{z' \subset x'} \frac{(M-|z'|)!(|z'|-1)!}{M!}[f^c h_x(z'))-f^c(h_x(z' \backslash i))]$$
위 식에서 $|z'|$은 $z'$의 non-zero entries의 갯수, $z'\subset x'$은 모든 $z'$ vectors, $z' \backslash i$는 $z_i'=0$ 셋팅을 의미한다.
다음으로, DeepLIFT는 다음과 같이 나타낸다. (Eq. 4)
$$\sum_i^n C_{\Delta x_i \Delta o}=\Delta_o$$
위 식에서 $o$는 target neuron의 output, $x=(x_1,...,x_n)$ 은 inputs, $r=(r_1,...,r_n)$은 reference values, $C_{\Delta x_i \Delta o}$는 $i$-th input의 contribution score, $\Delta x_i=x_i-r_i$, $\Delta o=f^c(x)-f^c(r)$을 의미한다.
위 식에서 $C_{\Delta x_i \Delta o}=\phi_i$, $f^c(r)=\phi_0$라고 하면, Eq 4와 Eq 2는 일치한다. 이는 DeepLIFT가 additive feature attribution method 임을 의미하고, SHAP values를 효과적으로 approximation 할 수 있음을 의미한다. (이 부분이 중요하다.)
3) 앞서 소개된 CAM, SHAP, Deep-LIFT를 바탕으로 LIFT-CAM을 유도해보자.
먼저, CAM에서는 $L_{CAM}^c$의 quality는 각 feature map에 대한 $\alpha = (\alpha_1,...,\alpha_{N_l})$에 의존한다. 따라서, 이 cofficients를 잘 정해주는 것이 중요하다. (기존 CAM에서는 fully connected layer가 이 weights을 구해주는 역할을 하였으나, 이를 DeepLIFT 방식으로 SHAP values를 estimation 하는 것이 핵심이다.)
제안되는 framework는 밑의 그림에 나와있다.
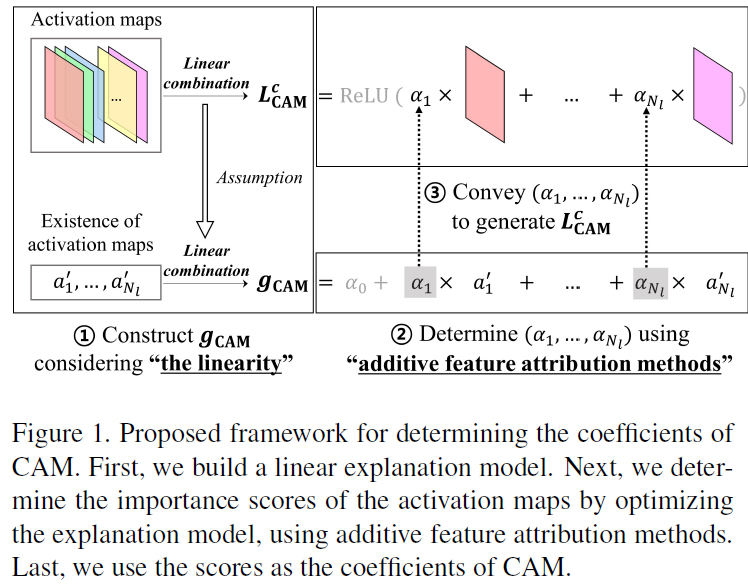
위 그림에서, $g_{CAM}$은 다음과 같이 나타낸다.
$$g_{CAM}(\alpha')=\alpha_0 +\sum_{k=1}^{N_l}\alpha_k \alpha_k'$$
위 식에서, $g_{CAM}$은 $f^c(x)$의 explanation model, $\alpha'\in \{ 0,1 \}^{N_l}$은 binary vector 을 의미한다. 이 vector에서 $\alpha_k'$가 1이 된다는 것은, $A_k$가 original activaiton values를 유지한다는 것이고, 0이 된다는 것은 $A_k$의 activation values가 0이 되는 것을 의미한다.
SHAP values는 다음과 같이 계산된다.
$$\alpha_k^{shap}=\sum_{\alpha'\subset A'}\frac{(N_l-|\alpha'|)!(|\alpha'|-1)!}{N_l!}[F^c(h_A(\alpha'))-F^c(h_A(\alpha'\backslash k))]$$
위 식에서, $F$는 original model $f$의 latter part로 $F(A)=f^{[L-1]}(x)$, $L$은 $f$의 전체 layers 갯수, $h_A$는 mapping function 으로 $A=h_A(A')$를 만족하는 함수, $A'$는 vector of ones를 의미한다.
위 식에서 $\alpha_k'=1$은 $A_k$로 mapping이 되고, $\alpha_k'=0$은 $A_k$와 같은 크기의 0으로 mapping이 된다.
최종적으로, $\alpha_k^{shap}$은 $A_k$의 SHAP values이다. (논문에서는 어떻게 SHAP values를 계산하고 추정하는 방법에 대해서 정리해놓았는데, 이 논문은 SHAP values를 DeepLIFT로 estimation 하는 것이 핵심임으로 이 부분은 궁금하면 읽어보길 추천한다.)
마지막으로, 신뢰성 있는 CAM을 만들기 위해서는 $\alpha^{shap}$를 잘 계산하는 것이 중요한데, 정확한 $\alpha^{shap}$을 계산하는 것은 불가능하다. 따라서, 저자는 approximation 방법을 제안하였다.
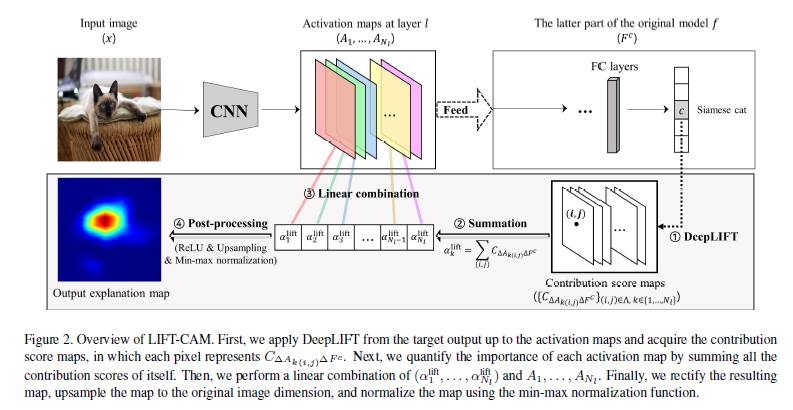
1) Single backward pass를 통해서 DeepLIFt를 사용해 layer $l$에서의 모든 neuron의 activations에 대한 contribution score를 계산한다.
$$\alpha_k^{lift}=C_{\Delta A_k \Delta F^c}=\sum_{(i,j)\in \Lambda} C_{\Delta A_{k(i,j)} \Delta F^c}$$
위 식에서 $\Lambda$는 ${1,...,H} \times {1,...,W}$로 $A_k$의 모든 location의 영역, $A_{k(i,j)}$는 $A_k$의 $(i,j)$ 영역에서의 activation value를 의미한다.
$\alpha^{lift}$는 $(\alpha_1^{lift},...,\alpha_{N_l}^lift)$로, 다음식을 만족한다.
$$\sum_{k=1}^{N_l}\alpha_k^{lift}=F^c(A)-F^c(0)$$
결과적으로, LIFT-CAM은 $\alpha^{shap}$을 $\alpha^{lift}$로 approximation 하는 방법이다. 밑의 개요도를 보면 쉽게 이해할 수 있을 것이다.
(다음으로, Ablation-CAM에 대한 내용이 나오는데, 대략적으로 저자들이 제안한 LIFT-CAM 방법이 더 efficient 하고, local accuracy를 만족한다고 생각하면 된다. 왜 그런지 이해하고 싶다면 논문을 읽어보길 바란다.)
4) 다음과 같은 평가를 하였다.
(1) $\alpha^{sharp}$와 $\alpha^{lift}$가 얼마나 가까운지에 대해서 평가.
(2) Grad-CAM, Grad-CAM++, XGrad-CAM, Score-CAM, Ablation-CAM과의 object recognition task 비교.
(3) 마지막으로, VQA task에 대한 평가.
평가를 위한 metrics로 Increase in Confidence (IC), Average Drop (AD), Average Drop in Deletion (ADD)와, Insertion과 Deletion에 대한 Area under probability curve를 사용하였다.
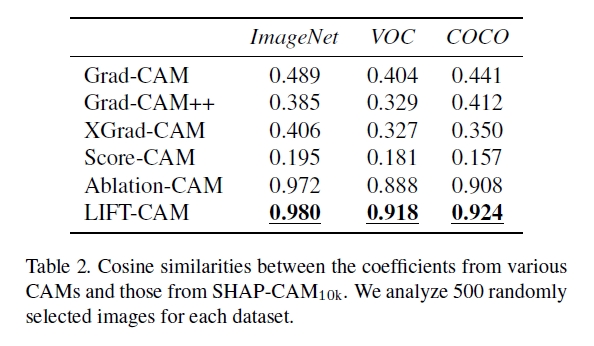
Object recognition에 대해서 SHAP-CAM은 $|\Pi|$ 가 커질 수록 성능이 향상되는 것을 보였으며, LIFT-CAM이 SHAP-CAM100과 비교할 때, 가장 유사한 cofficients를 가지고 있음을 보였다.

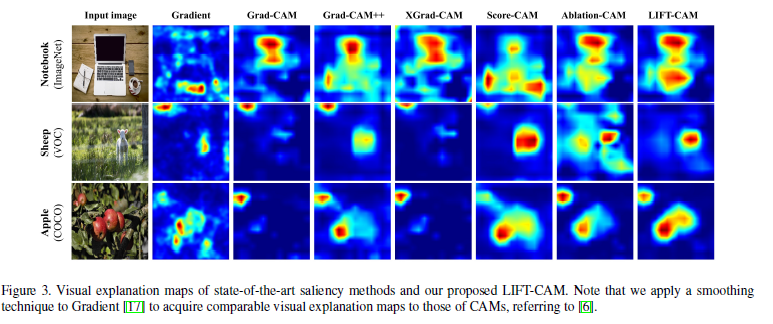
또한, visual explanation 평가에서는, LIFT-CAM이 object를 잘 recognize하고 localize하고 있으며 multiple object에서도 잘 localize하고 있음을 보여주고 있다.
다른 방법과의 비교에서, LIFT-CAM이 성능이 우수하다는 것을 확인 할 수 있다.
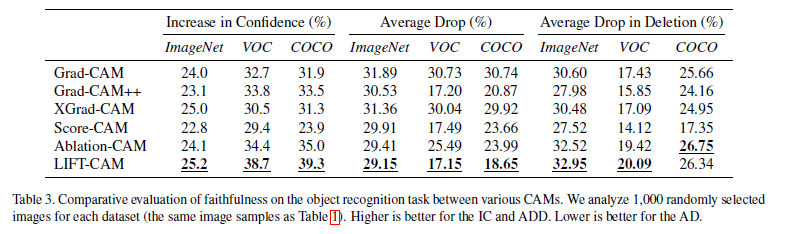
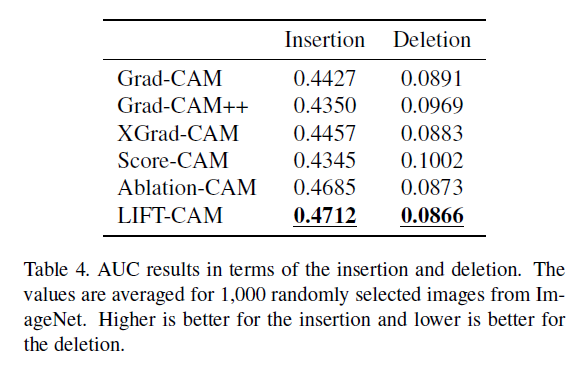
Localization evaluation 에서도 기존 방법대비 LIFT-CAM이 더 나은 proportion으로 bounding box와 겹침을 알 수 있다.

마지막으로, VQA task에서 LIFT-CAM이 Grad-CAM 보다 더 나은 성능을 보여줌을 알 수 있다.

+
이 논문의 핵심은 기존 explainable AI에서 사용되었던 SHAP을 사용함으로써, 기존 CAM에서 사용된 weights을 좀 더 여러 조건들을 만족하도록 하여 더 나은 explanation map을 만드는 것이다. 이때, SHAP 을 그대로 계산하는것 대신에 DeepLIFT를 사용하여 $\alpha^{shap}$을 $\alpha^{lift}$로 추정하는 방법을 사용했다는 것이 가장 중요하다. 결과적으로 이렇게 추정된 importances는 기존 방법대비 더 나은 성능을 보여주었을 뿐만 아니라, SHAP values을 잘 근사하고 있음을 보여주었다.



