
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- grad-cam
- 설명가능한
- Deep learning
- coding test
- Class activation map
- SmoothGrad
- Machine Learning
- 인공지능
- 코딩 테스트
- Explainable AI
- Score-CAM
- Interpretability
- keras
- 백준
- 기계학습
- Cam
- Unsupervised learning
- GAN
- cs231n
- 설명가능한 인공지능
- 머신러닝
- AI
- Artificial Intelligence
- 메타러닝
- python
- meta-learning
- 딥러닝
- 시계열 분석
- 코딩테스트
- xai
- Today
- Total
TestK
Generative Adversarial Networks 본문
Generative Adversarial Networks (GAN)
두 신경망이 '경쟁'하면서 서로 학습하는 재미있는 아이디어를 가진 network를 Generative adversarial networks 라고 부른다. 두개의 신경망 중 하나는 1. Generative model, 2. Discriminator모델이다. 흔히 이 모델을 설명할 때 위조지폐를 만드는 범인과 이를 감독하는 경찰의 예를 든다. 경찰은 범인이 만든 위조 지폐를 구분을 하고, 거짓인지 진짜인지를 밝힌다. 범인은 이런 과정을 보고 경찰을 속이기 위해서 더 나은 위조 지폐를 만들어 낸다. 그러면 경찰은 다시 더 정밀하게 구분하도록 학습을 하게되고.. 최종적으로는 경찰은 위조 지폐를 분류할 거짓이라고 확률이 50 %가 될 정도로 정밀하게 위조 지폐가 만들어진다. 이렇게 경쟁을 하면서 거짓 데이터를 실제 데이터와 비슷하게 만들어내는 과정을 GAN은 포함하고 있다.
더 자세하게 말하자면, Real dataset의 probability distribution을 학습해서 비슷한 probability distribution을 갖는 Fake dataset을 생성해내는 것이다. 일단 GAN은 실제 데이터는 1로, 거짓 데이터는 0으로 분류하도록 Discriminator 모델을 학습시킨다. 단순히 이 정도의 labeling만 해주기 때문에 unsupervised learning으로, 우리가 정확하게 이런 이미지라는 것을 보여주지 않아도 Generative model은 실제 이미지와 비슷한 허구 이미지를 생성해낸다.
Generative에 입력되는 데이터는 random noise가 입력된다. 그리고 출력되는 형태는 입력된 random noise보다 더 높은 dimension을 갖게 된다. Generative model의 목적은 생성된 허구 이미지가 실제 이미지와 비슷하고 'probability distribution'이 최대한 같도록 이미지를 만들어내는 것이다.
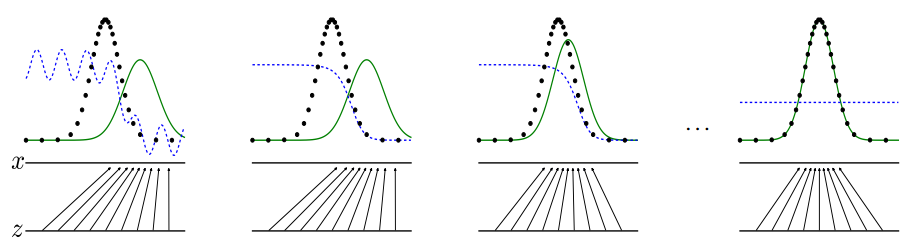
파란색 점선 : 실제와 허구 확률의 분포 차이
초록색 실선 : 허구 확률 분포
검정색 점선 : 실제 확률 분포
Generative model이 학습이 되면서 초록색 실선의 확률 분포가 검정색 점선의 확률 분포에 일치해지는 모습을 확인할 수 있다. 이렇듯 처음에 주어지는 입력 확률 분포를 실제 데이터가 갖고 있는 확률 분포에 갖도록 해서 실제와 비슷한 형태의 데이터를 생성해내는 것이다.
학습 순서는 다음과 같다.
1. Generative model에서 random uniform distribution의 입력을 받아서 허구의 data를 생성한다.
2. 허구의 data와 실제 data를 섞어서 discriminator model를 학습시킨다.
3. discriminator와 generative model이 연결된 하나의 네트워크를 허구의 data가 실제로 인식되도록 학습시킨다. 이 때 discriminator는 학습될 필요가 없으므로 trainable을 false로 설정한다.
결국, 판별식은 얼마나 실제 데이터와 허구 데이터가 차이나는지 오차를 backpropagation으로 전달하게 되고 이는 generative model의 신경망의 weights을 수정하여, 입력된 random uniform distribution이 실제 data의 probability distribution과 같도록 학습을 한다.
MNIST를 적용할 때의 각 epoch마다 16개 batch에서 생성된 숫자의 변화를 다음은 보여주고 있다.











위는 epoch 0을 100단위로 999까지 나타낸 결과이다. 학습이 진행될 수록 generative model은 실제 숫자와 가까운 형태를 만들어 내는데, 아직 확실하게 어떤 숫자인지 판단하기 어렵다. 더 잘 generative하기 위한 여러 모델이 제시되었다. BEGAN, Disco-GAN등 다양한 GAN들을 다음에는 구현해볼 생각이다.
'Deep learning > Keras' 카테고리의 다른 글
| You Only Look Once : Unified Real-Time Object Detection (0) | 2018.07.27 |
|---|---|
| Show and Tell: A Neural Image Caption Generator (2) | 2018.07.26 |
| Variational Auto-Encoder (VAE) (0) | 2018.07.11 |


